
章節目錄
1 : 建立Series
2 : 建立DataFrame
3 : 資料讀取
4 : 數據處理
✦ 1 : 建立Series
1-1 pandas基本介紹
pandas是Python中非常常用的package,主要用來作資料處理和數據分析,不但提供了Series、DataFrame等容易使用的資料結構外,也提供了超好用的函數和功能,如果不會pandas別說你是資料科學家哦!
- 如果使用colab的話要先安裝pandas指定版本
!pip install pandas==1.3.5
- 查看pandas版本
# 使用套件前需要先import套件名稱
import pandas as pd # 使用時將pandas命名為pd方便呼叫
pd.__version__
1-2 什麼是Series ?
Series專門用來處理單維度(一維陣列)的資料,以Excel來說,就是只有單筆資料。
index |
data |
|---|---|
| 0 | 12 |
| 1 | 14 |
| 2 | 15 |
| 3 | 13 |
1-3 建立Series
只要將陣列資料放入pd.Series中就可以囉~
lists = [10,20,30,40,50] # 單維度資料
s = pd.Series(lists) # 用pd組合成Series
s
# 輸出值:
0 10
1 20
2 30
3 40
4 50
1-4 建立時間序列的Series
若沒特別設定index的話預設會是0、1、2、3……,但通常資料會是時間搭配數據的形式。
例如:每天溫度紀錄、每日股價數據等等。
price = [20,23,24,22,25,27]
date = pd.date_range('2023-01-01','2023-01-06')
s = pd.Series(price,index=date) # 設定index為date
s
# 輸出值:
2023-01-01 20
2023-01-02 23
2023-01-03 24
2023-01-04 22
2023-01-05 25
2023-01-06 27
✦ 2 : 建立DataFrame
2-1 什麼是DataFrame ?
DataFrame是處理多維度(二維陣列)的資料,使用方式為:
pd.DataFrame(資料,index=索引,columns=欄位)
index |
data 1 |
data 2 |
|---|---|---|
| 0 | 12 | 21 |
| 1 | 14 | 24 |
| 2 | 15 | 23 |
| 3 | 13 | 22 |
2-2 建立DataFrame
資料可以是list、dict或Series來丟入pd.DataFrame中,index是縱向的資料索引、columns是橫向的欄位名稱。
建立一個二維的DataFrame:
data = {
'data 1':[100,102,106,111,109,108],
'data 2':[11,15,16,14,15,12]
}
date = pd.date_range('2023-02-01','2023-02-06')
df = pd.DataFrame(data,index=date)
df
# 輸出值:
index data 1 data 2
2023-02-01 100 11
2023-02-02 102 15
2023-02-03 106 16
2023-02-04 111 14
2023-02-05 109 15
2023-02-06 108 12
另外一種寫法是省略掉命名data的步驟,直接丟到在函數裡:
date = date = pd.date_range('2023-02-01','2023-02-06')
df = pd.DataFrame({
'data 1':[100,102,106,111,109,108],
'data 2':[11,15,16,14,15,12]
},index=date)
df
✦ 3 : 資料讀取
3-1 讀取資料格式
pandas可從網站、csv、Excel、資料庫中讀取資料,匯入pandas後進行數據清理、分析或繪製圖表。
常用方式:
- read_csv ► 讀取csv檔
- read_html ► 讀取網頁中表格資料
- read_json ► 讀取json檔
- read_sql ► 讀取SQLite資料庫資料
3-2 讀取網頁中表格
讀取台灣銀行匯率的換匯表格
import pandas as pd
url = 'https://rate.bot.com.tw/xrt?Lang=zh-TW' # 輸入網站網址
pd.read_html(url)[0] # 選取第0個表格
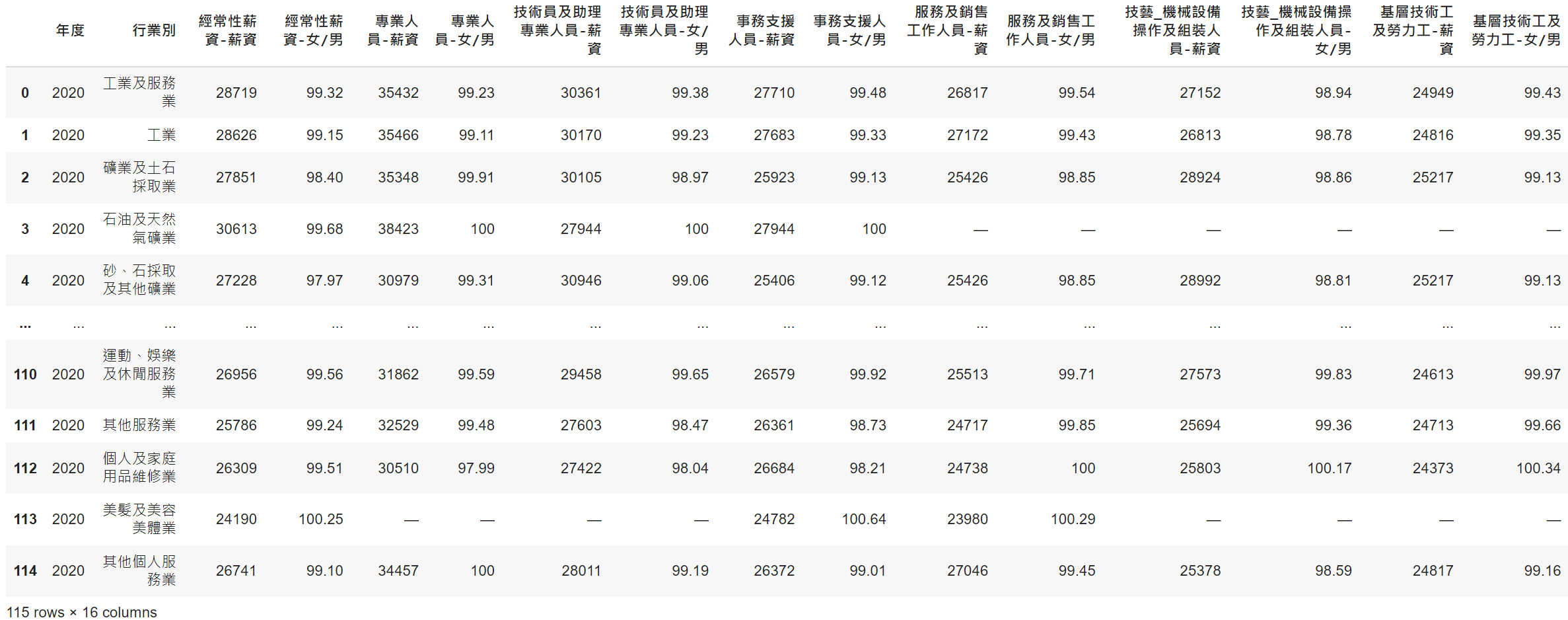
3-3 讀取csv檔
首先到政府資料開放平台 ➨ 選擇求職及就業 ➨ 選擇瀏覽次數多至少 ➨ 點選初任人員每人每月經常性薪資 ➨ 下載109年各職類別初任人員每人每月經常性薪資─按行業別分的csv檔。
- 在本地端的Jupyterlab上執行的話,將csv檔存在
目前所在資料夾
import pandas as pd
data = pd.read_csv('A17000000J-020066-tqz.csv')
data
- 在Colab上執行的話,將csv檔存在雲端硬碟內的
Colab Notebooks
import pandas as pd
from google.colab import drive
drive.mount('/content/drive')
data = pd.read_csv('drive/MyDrive/Colab Notebooks/A17000000J-020066-tqz.csv')
data
✦ 4 : 數據處理
4-1 查看資料資訊
在獲取資料後通常需要先確認資料內數據的格式,像是資料中的數字是否為int/float(數值)格式,若是str(字串)則需要透過pandas將字串轉成數值才能進行計算分析。
以上面的csv檔為範例:
data.dtypes
# 輸出值:
年度 int64
行業別 object
經常性薪資-薪資 int64
經常性薪資-女/男 float64
專業人員-薪資 object
專業人員-女/男 object
技術員及助理專業人員-薪資 object
技術員及助理專業人員-女/男 object
事務支援人員-薪資 object
事務支援人員-女/男 object
服務及銷售工作人員-薪資 object
服務及銷售工作人員-女/男 object
技藝_機械設備操作及組裝人員-薪資 object
技藝_機械設備操作及組裝人員-女/男 object
基層技術工及勞力工-薪資 object
基層技術工及勞力工-女/男 object
dtype: object
4-2 資料處理
從output來看,專業人員-薪資的格式是object(字串),對於Python來說是無法進行計算,所以即使表格上顯示的是數字,但實際上仍是文字,接下來就是要將object轉成float的格式。
首先先篩選出要轉換的columns(欄位名稱)
# 除了年度和行業別外都要轉成數值
# data.columns[2:] 表示選取第2個columns名稱(經常性薪資-薪資)之後的;2:表示從2開始往後數
col = data.columns[2:]
data[col] # []內放入要選取的columns欄位
# 字串轉數值
# applymap為針對每一列去套入函式內
# lambda為簡化版的def函式,冒號左邊為參數,右邊為函式內容
# 使用pd.to_numeric將str轉成float,errors='coerce'表示若無法轉換則顯示Nan
data[col] = data[col].applymap(lambda s:pd.to_numeric(str(s),errors='coerce'))
data.dtypes
# 輸出值:
年度 int64
行業別 object
經常性薪資-薪資 int64
經常性薪資-女/男 float64
專業人員-薪資 float64
專業人員-女/男 float64
技術員及助理專業人員-薪資 float64
技術員及助理專業人員-女/男 float64
事務支援人員-薪資 float64
事務支援人員-女/男 float64
服務及銷售工作人員-薪資 float64
服務及銷售工作人員-女/男 float64
技藝_機械設備操作及組裝人員-薪資 float64
技藝_機械設備操作及組裝人員-女/男 float64
基層技術工及勞力工-薪資 float64
基層技術工及勞力工-女/男 float64
dtype: object
詳細程式碼可點擊掌握Pandas資料科學技巧
以上範例都幫大家寫好囉!建議實際練習會學得更快哦~
結論
本單元詳細介紹了資料科學家必學的pandas,並實際演練如何從網站上讀取表格以及讀取下載下來的csv檔,最後進行數據處理,將資料中的數字成功轉成數值,方便未來進行計算以及數據分析哦!
如果對於Python基礎語法還不熟悉的可以參考前一篇:
進入Python的第一堂課 | 一小時上手Python基礎語法